



If you have problems with opening text or CSV file in Exportizer or its field structure is not as you expected, it probably means that the file does not have a schema describing its field structure or the schema was incorrectly defined. In such cases, you should create or edit the schema. We recommend that each such a file has a schema. Schemas are located in separate files (schema files), therefore creating, deleting, or changing the schema will not change the corresponding text or CSV file (data file). If data file does not have a corresponding schema file, the schema is built in memory using defaults which may be not desirable in many cases.
Schema files are plain text files which must be placed in the folder, where data files are located. For BDE connections, schema file must have the same file name as the data file, but with .SCH extension. For ADO connections, the schemas for all data files from certain folder are always kept in one file file named Schema.ini.
The schemas can be created or edited in any text editor. Please read ADO or BDE documentation for details.
You can also create a schema automatically in Exportizer by exporting data to CSV/text file.
In Exportizer, when you try to open text table without the schema of field definitions, a prompt appears asking whether to create the schema. If you confirm, a new window window will appear where you can define the schema in convenient visual mode and see how this will affect the table data view.
Schema Example 1
The fields in the data file are separated by vertical bar characters (|).
Contents of the data file (programs.txt):
1|Database Tour|www.databasetour.net|6848
2|Database Tour Pro|www.databasetour.net|7232
3|Exportizer|www.vlsoftware.net/exportizer|4267
4|Exportizer Pro|www.vlsoftware.net/exportizer|5699
5|Exportizer Enterprise|www.vlsoftware.net/exportizer|5742
6|Icons from File|www.vlsoftware.net/icons-from-file|1890
7|Rename Us|www.vlsoftware.net/rename-us|3166
8|Rename Us Pro|www.vlsoftware.net/rename-us|4581
9|Free Renju|www.vlsoftware.net/free-renju|404
10|Logical Crossroads|www.vlsoftware.net/logical-crossroads|522
11|Hanoi Towers|www.vlsoftware.net/hanoi-towers|99
12|Reportizer|www.reportizer.net|6211How this file looks without schema (ADO connection):
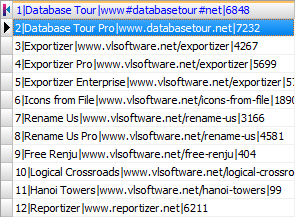
Contents of the schema files:
BDE schema file (programs.sch):
[programs]
CHARSET = ASCII
FILETYPE = VARYING
DELIMITER = |
Field1 = ID,NUMBER,18,0,0
Field2 = NAME,CHAR,30,0,18
Field3 = URL,CHAR,50,0,48
Field4 = SIZEKB,NUMBER,18,0,98ADO schema file (Schema.ini):
[programs.txt]
ColNameHeader=False
Format=Delimited(|)
CurrencyThousandSymbol=
CurrencyDecimalSymbol=.
DecimalSymbol=.
TextDelimiter=
MaxScanRows=25
CharacterSet=ANSI
Col1=ID Integer Width 18
Col2=NAME Char Width 30
Col3=URL Char Width 50
Col4=SIZEKB Integer Width 18How this file looks with schema:
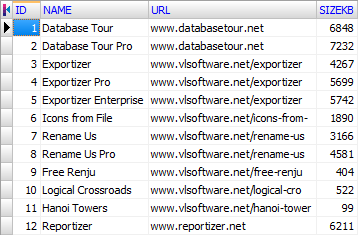
Schema Example 2
The fields in the data file are separated by commas. The field data which contain commas, are delimited by double quote marks.
Contents of the data file (PAYMENT.txt):
1,1,2/7/2017,300
2,4,2/8/2017,3467.35
3,5,3/20/2017,21.89
4,6,3/20/2017,250.5
5,7,4/26/2017,121
6,2,5/2/2017,19
7,3,5/4/2017,1457
8,11,9/17/2022,333
9,11,9/17/2022,333
10,11,9/17/2022,333How this file looks without schema (BDE connection):
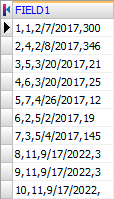
Contents of the schema files:
BDE schema file (PAYMENT.sch):
[PAYMENT]
CHARSET = ASCII
FILETYPE = VARYING
QuoteChar ="
SEPARATOR =,
Field1 = PAYMENT_ID,NUMBER,18,0,0
Field2 = CUSTOMER_ID,NUMBER,18,0,18
Field3 = PAYMENT_DATE,CHAR,20,0,36
Field4 = PAYMENT_SUM,FLOAT,20,2,56ADO schema file (Schema.ini):
[PAYMENT.txt]
ColNameHeader=False
Format=CSVDelimited
CurrencyThousandSymbol=
CurrencyDecimalSymbol=.
DecimalSymbol=.
TextDelimiter=
MaxScanRows=25
CharacterSet=ANSI
Col1=PAYMENT_ID Float Width 20
Col2=CUST_ID Float Width 20
Col3=PAY_DATE Date Width 20
Col4=PAY_SUM Float Width 20How this file looks with schema:
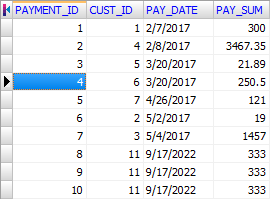
Schema Example 3
The fields in the data file have fixed width.
Contents of the data file (customer.txt):
1 Sandra Bush Portland United States
2 Eric Miles Edmonton Canada
3 Berndt Mann Hamburg Germany
4 Marek Przybylsky Krakow Poland
5 John Hladni Bedford United States
6 Bogdan Vovchenko Kyiv Ukraine
7 Paul Vogel Hamburg Germany How this file looks without schema (ADO connection):
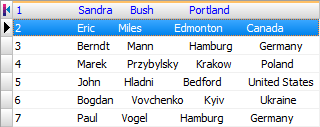
Contents of the schema files:
BDE schema file (customer.sch):
[customer]
CHARSET = ASCII
FILETYPE = FIXED
Field1 = ID,FLOAT,20,2,0
Field2 = FIRSTNAME,CHAR,12,0,20
Field3 = LASTNAME,CHAR,16,0,32
Field4 = CITY,CHAR,16,0,48
Field5 = COUNTRY,CHAR,16,0,64ADO schema file (Schema.ini):
[customer.txt]
ColNameHeader=False
Format=FixedLength
FixedFormat=RaggedEdge
MaxScanRows=25
CharacterSet=ANSI
Col1=ID Float Width 20
Col2=FIRSTNAME Char Width 12
Col3=LASTNAME Char Width 16
Col4=CITY Char Width 16
Col5=COUNTRY Char Width 16How this file looks with schema:
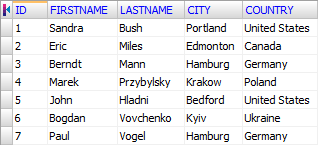
Practical Cases
- Creating Schema for a Text Table
- Exporting Data to SQL File(s)
- Exporting Large Tables
- Exporting Calculated Fields
- Exporting BLOBs to Individual Files
- Exporting to HTML Using Template
- Importing Database Files from Explorer